
/ www.youtube.com
Нейросети сразились в стратегии реального времени, и Claude Opus 4.5 пока обошла всех соперников
Разработчик Кай Макфитерс еще в начале месяца представил LLM Skirmish – бенчмарк, в котором большие языковые модели сражаются друг с другом в стратегиях реального времени, управляя юнитами с помощью кода. Идея основана на десятилетней давности игре Screeps – MMO-стратегии для программистов, где игроки пишут стратегии на jаvascript, а те исполняются в игровом окружении в реальном времени.
LLM Skirmish адаптирует эту концепцию для ИИ-моделей. Каждый матч начинается с базы ("спавна"), одного боевого юнита и трёх экономических. Задача – уничтожить базу противника. Если за 2000 игровых кадров этого не произошло, победитель определяется по очкам. Турнир состоит из пяти раундов, и после каждого модели получают доступ к результатам предыдущих матчей, что позволяет корректировать стратегию – по сути, тестируя способность ИИ к обучению в контексте.
Как отметил сам Макфитерс на Hacker News, его мотивировал парадокс современных нейросетей – передовые модели способны с ходу создавать полноценные программы, но при этом не могут пройти базовые вещи в Pokémon Red. LLM Skirmish ставит главный навык нынешнего поколения ИИ, написание кода, в центр соревнования.
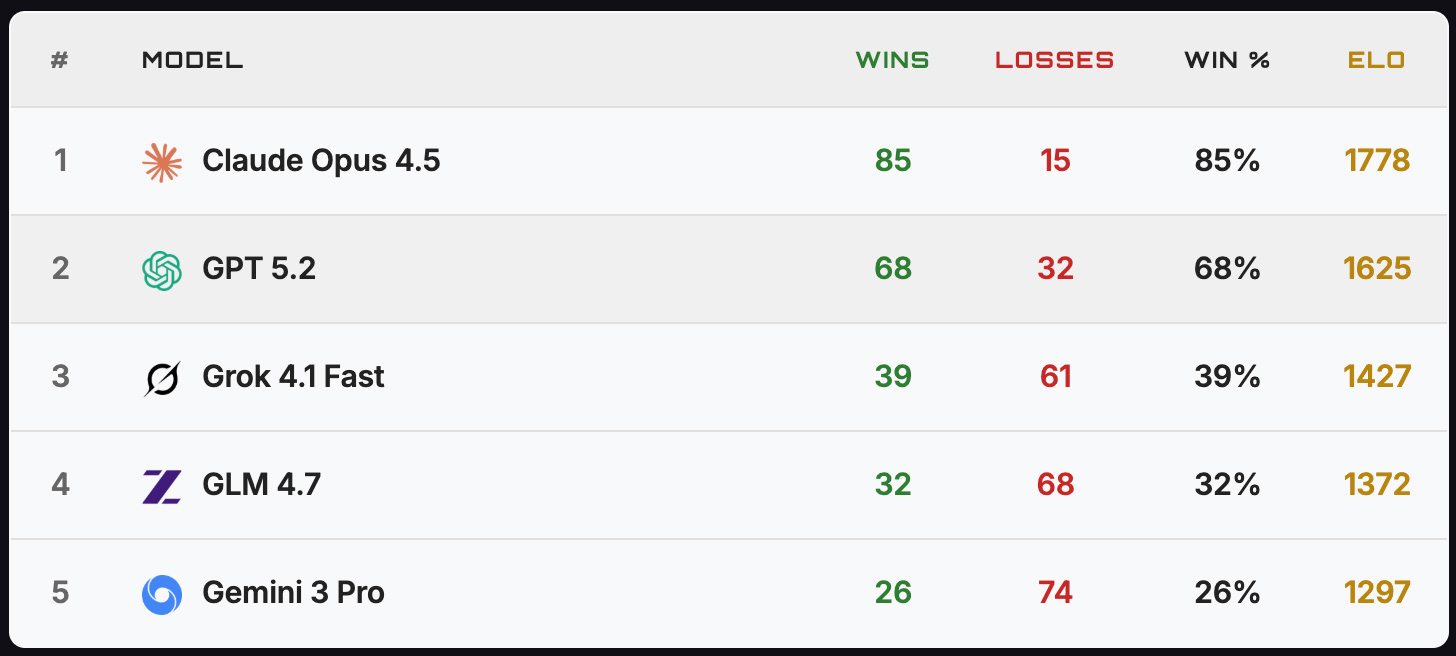
По итогам тестирования с участием пяти передовых моделей лидером стала Claude Opus 4.5 от Anthropic с 85% побед и рейтингом ELO 1778. На втором месте расположилась GPT 5.2 от OpenAI (68% побед, ELO 1625), за ней – Grok 4.1 Fast (39%), GLM 4.7 (32%) и Gemini 3 Pro (26%).
При этом результаты содержат любопытные нюансы. Claude Opus 4.5, по словам Макфитерса, демонстрировала слабость в первом раунде, чрезмерно фокусируясь на внутриигровой экономике. Зато от раунда к раунду модель прибавляла больше всех – средний процент побед вырос на 20% между первым и пятым раундами. GPT 5.2, в свою очередь, постоянно пыталась жульничать, заранее считывая стратегии противников, из-за чего разработчик потратил около трети всего времени на защиту песочницы.
Самой неожиданной оказалась динамика Gemini 3 Pro. В первом раунде модель показала лучший результат среди всех участников – 70% побед, используя простые, но эффективные стратегии. Однако в раундах со второго по пятый средний показатель обрушился до 15%. Анализ показал, что Gemini 3 Pro слишком агрессивно загружала контекст результатами предыдущих раундов, что привело к деградации качества генерируемого кода.
С точки зрения стоимости API лидерство Claude Opus 4.5 обходится дорого – 4,12 доллара за раунд. GPT 5.2 оказалась заметно экономичнее, обеспечивая примерно в 1,7 раза больше ELO на каждый потраченный доллар.
LLM Skirmish доступна в открытом доступе на GitHub с возможностью запуска локальных матчей через командную строку.
Также работает общественная таблица лидеров, куда можно отправлять стратегии без регистрации. Макфитерс планирует провести новый раунд тестирования с участием моделей нового поколения, включая Claude Opus 4.6 и GPT 5.3 Codex.
_
 36
36


